Depuis septembre 2017, le plan cadastral est publié en Opendata. Il est distribué en Geojson, en shapefile et en Edigeo par etalab. Il est alors possible de s’appuyer sur les 2 premiers formats pour importer les données dans Postgresl avec ogr2ogr par exemple
Néanmoins, ces données ne sont pas complètes, certaines couches sont absentes ainsi que certains objets… On y reviendra plus bas.
Le format d’origine, celui fourni par la DGFiP est l’Edigeo, cela fait donc sens de partir de la source pour importer ces données ! Toujours privilégier les circuits courts, éviter les intermédiaires !
Justement, cela tombe bien, j’ai créé edigeoToGeojson il y a déjà 2 ans, une librairie totalement originale en JavaScript qui permet de parser l’Edigeo en Geojson à la vitesse de la lumière! D’ailleurs il a toujours 0 étoile sur Github… :’(
Bref, le script que je vous présente aujourd’hui s’appuie très largement sur edigeoToGeojson. Vous l’aurez compris il permet d’importer les Edigeo dans une base postgresql/postgis de la façon la plus simple, la plus fiable, la plus rapide
Installation de cadastre-pg
Il vous faudra bien sûr Node.js sur votre poste ainsi qu’une base de données Postgresql/postgis Personnelement j’utilise Docker pour ma base Postgis, c’est simple et rapide
sudo docker run --name=postgis -d -e POSTGRES_USER=fabien -e POSTGRES_PASS=password -e POSTGRES_DBNAME=gis -e ALLOW_IP_RANGE=0.0.0.0/0 -p 5432:5432 -v /data/postgresql:/var/lib/postgresql --restart=always kartoza/postgis:12.0
Le script est présent sur npm, il est donc possible de l’installer directement avec cette ligne :
npm install -g cadastre-pg
Utilisation en ligne de commande
L’utilisation est particulièrement simple. Pour importer les Edigeo de 2019 qui se trouvent dans le répertoire /data/EDIGEO/dep2A vers la base postgis “gis” sous le schema “cadastre” en utilisant le srid 4326 :
cadastre-pg --path "/data/EDIGEO/dep2A" --srid 4326 --config "full" --schema "cadastre" -y 2019 --dep "fromFile" --host "localhost" --database "gis" --user "fabien" --port 5432 --password "password"
Les données sources doivent être au format tar.bz2, après les avoir téléchargé sur cadastre.data.gouv.fr, il faudra les deziper.
Le script se chargera de décompresser les archives bz2, récupérera le SRID des données sources, reprojectera les données à la volée si besoin. Il pourra même déterminer le code du département de la feuille en cours d’import. Il se chargera également de créer le schema les tables et les index qui vont bien. Il est possible de supprimer le schema avant l’import en lui passant le flag –dropSchema, ou alors juste les tables utilisées ( –dropTable)
Rapide
Toutes les opérations se font sur Node, il n’y a pas de calculs sur Postgresql, pas de table temporaire, etc… On se contente de lui insérer des lignes par millions…
Voici un benchmark rapide, sur un petit, un moyen et un gros département en comparant avec l’import des Edigeo de Qgis (plugin cadastre qui utilise ogr2ogr) Le PC servant au test a un CPU AMD 2700X et un SSD sous Ubuntu 19.10, Node 12.
| Département | cadastre-pg | plugin cadastre de Qgis |
|---|---|---|
| 2A (189 Mo) | 53 s (0.88 min) | 1314 s (22 min) |
| 2B (367 Mo) | 93 s (1.55 min) | |
| 38 (722 Mo) | 230 s (3.83 min) | 6355 s (106 min) |
.
cadastre-pg est donc en 22 et 27 fois plus rapide…
Fiable
Le format Edigeo peut être assez complexe, et selon les scripts utilisés certaines géométries peuvent ne pas être correctement générées. J’ai comparé les parcelles exportées par Etalab en Shapefile avec celles issues de cadaste-pg.
On retrouve quelques parcelles manquantes chez Etalab, elles ont toutes en communs d’avoir un “trou” qui touche l’un des bords de parcelle. Voici 2 exemples en images parmi la dizaine que j’ai trouvés sur le département 38.
En marron les objets présents sur les 2 couches, en rose les objets uniquement présents dans les données générées par cadastre-pg
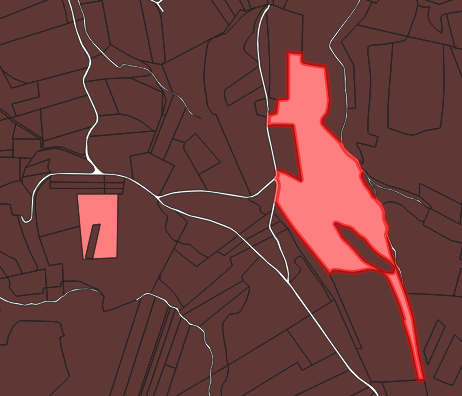
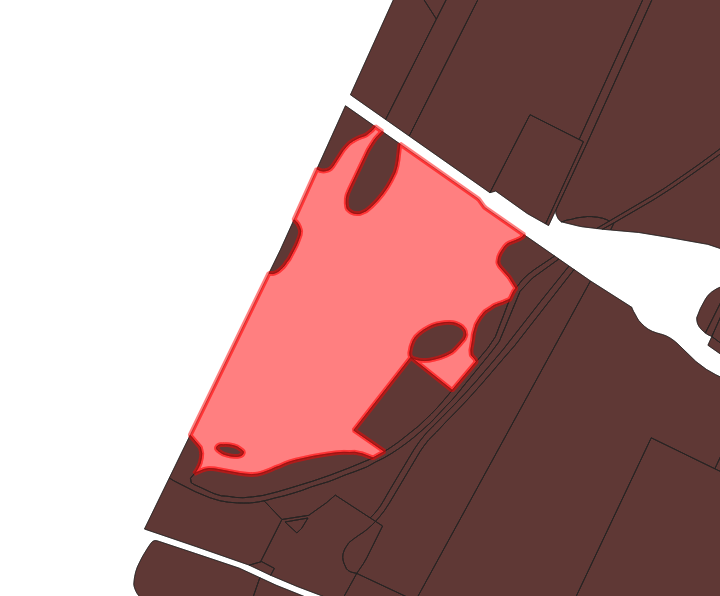
A noter que l’import avec le plugin cadastre de Qgis ne génere pas ces erreurs et les géométries semblent être rigoureusement les mêmes
Souple
Il est possible de paramétrer l’import en utilisant un fichier de configuration. Par défaut, il en existe 3, full/light/bati
Ceux-ci permettent de configurer la création des tables, le maping entre les champs, et même de modifier les données à la volée.
Pour utiliser une configuration par défaut, il suffit d’indiquer l’identifiant (eg le nom du fichier) dans le flag –config Il est également possible d’utiliser votre propre fichier de configuration en indiquant dans ce même flag le chemin de votre fichier JSON
Github
Vous pouvez retrouver les sources et d’autres infos sur Github